The transitive Property
You may recall the transitive property from elementary school math class. It states:
If A = B, and B = C, then A = C
The SQL Server optimizer can and will use this property, and it can lead to issues in your queries. When I’m writing a query, I have a clear idea of how I want it to operate. But using the transitive property, SQL Server has additional options one might not expect, and this may occasionally cause things to go awry. Consider this:
DECLARE @OrderID INT = 110001;
SELECT
so.CustomerID,
so.OrderID,
so.CustomerPurchaseOrderNumber,
sol.OrderLineID,
sol.StockItemID,
sol.Quantity,
sol.UnitPrice
FROM Sales.Orders so
JOIN Sales.OrderLines sol
ON sol.OrderID = so.OrderID
WHERE
so.OrderID = @OrderID;
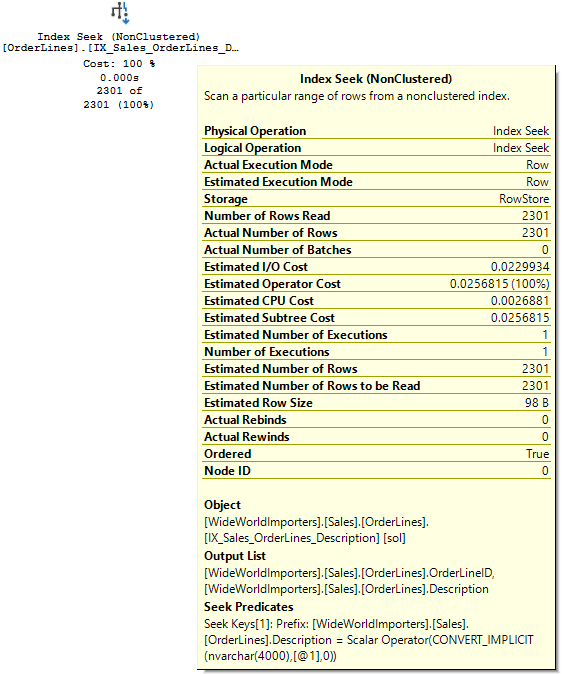
I’d expect the optimizer to seek the Orders table, then join to OrderLines. But since @OrderID is also equal to sol.OrderID, it could start the query there. There would be little difference; the OrderID column is indexed in both tables and neither table is that large. There’s only 3 OrderLines for this OrderID.
But what if:
- The CustomerID was present in all tables. And was part of the primary key in each.
- The data set was larger, with 100’s of millions of rows in our OrderLines table.
- Statistics were last updated by an auto-update. A table of this size would have a very small sampling rate by default, <1%.
- Our database has a large number of customers, and we’re running a query to get recent orders for a large customer that haven’t been picked yet.
We may end up with a query like this:
DECLARE
@CustomerID INT = 55;
SELECT
so.CustomerID,
so.OrderID,
so.CustomerPurchaseOrderNumber,
so.OrderDate,
sol.OrderLineID,
sol.StockItemID,
sol.Quantity,
sol.UnitPrice
FROM Sales.Orders so
JOIN Sales.OrderLines sol
ON sol.OrderID = so.OrderID
AND sol.CustomerID = so.CustomerID
WHERE
so.CustomerID = @CustomerID
AND so.OrderDate > DATEADD(DAY,-90,GETDATE())
AND so.PickingCompletedWhen IS NULL;
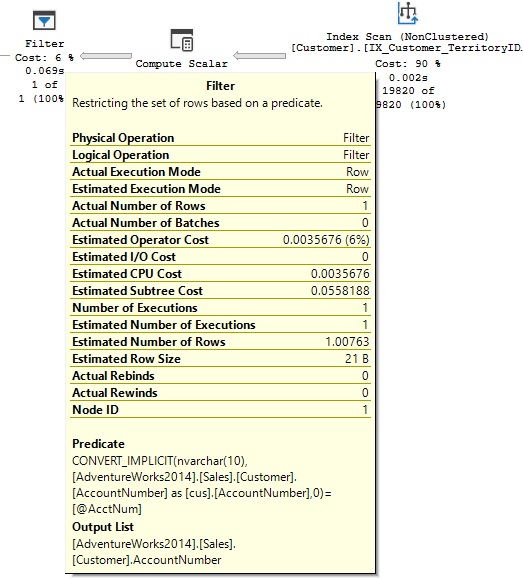
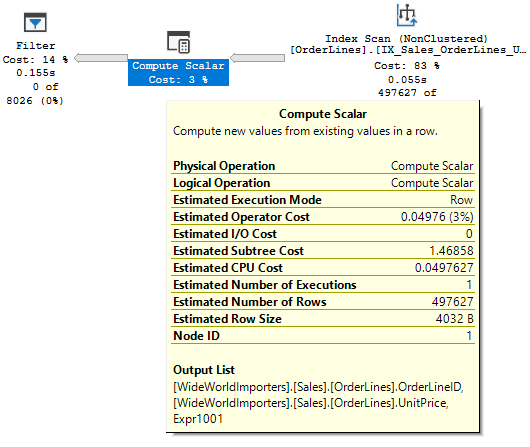
If our PK has the CustomerID first, we could use that to search either table. If we don’t have an index with the CustomerID and our dates on Orders, those fields will be in our predicate, not our seek predicate. With poor statistics, the optimizer may seek OrderLines first, returning all lines for that customer, before later joining an filtering it down. In this situation, that could be a mountain of reads.
Countering The transitive Property
So what if you experience or anticipate this issue with a query? I see a few approaches to prevent the bad plan from sneaking up on your server.
- Join Hints or Force Order: The FORCE ORDER hint would direct the optimizer to hit the Orders table first. A join hint like INNER LOOP JOIN would set the join type, and also force the order. Either would results in seeking the Orders table before joining to OrderLines, preventing our worst case.
- Index hints: If you hint the optimizer to use an index based on CustomerID and OrderDate, that would point it in the direction of using the Orders table first, avoiding the problem.
- Better stats: An argument can definitely be made to not use auto-updated stats on a sufficiently large table. I’ve seen sampling rates below 0.1%, and mistakes can be made then. If you updated stats with a large sampling rate, the optimizer will have better information to work with, and that may avoid the worst case.
I thought this property of the optimizer was interesting when I first saw it in play, and I haven’t seen it referred to much. Hopefully this post will give you a little more insight into what the optimizer can do, and how we sometimes need to respond.