Understanding Cost in SQL Server
Cost is an important concept in SQL Server. It is key in how plans are compared and chosen by the optimizer, and it can guide us to problem operators as we tune a query’s performance. It can also lead us astray if we follow it blindly. In this post, I want to explain what cost is and how we use it.
Many queries (that aren’t trivial) can be executed in a number of different ways. Each index on a table is a possible path for the optimizer to use, and statistics allow the optimizer to determine the cost of a given operation. SQL Server determines what potential plan it will use in large part based on cost. The optimizer isn’t exhaustive. It won’t compare all possible plans; that would take too long.
Let’s take a look at an example query from the AdventureWorks database.
SELECT * FROM Sales.vSalesPersonSalesByFiscalYears
WHERE SalesPersonID=278
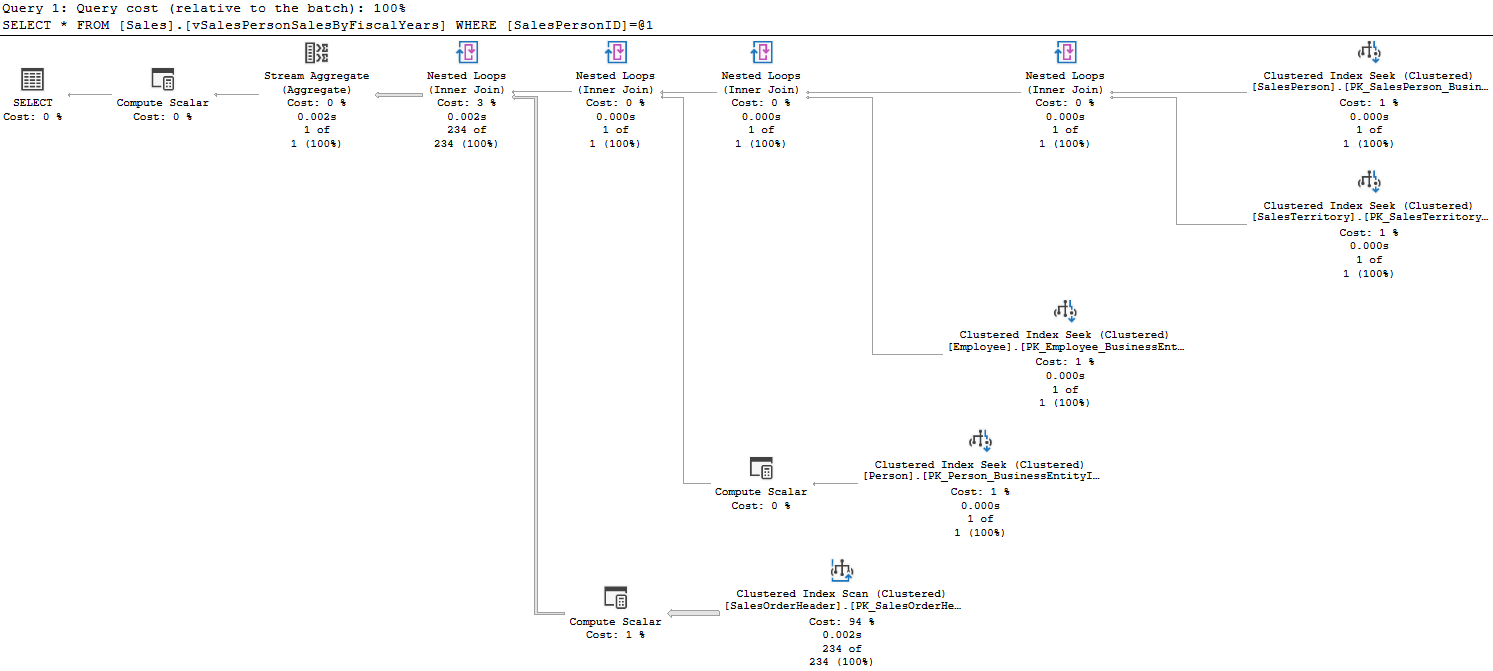
There is a cost provided for each query relative to the batch; that can help you narrow down which statement is the issue if a large batch or procedure is performing poorly. This query is in the only one in the batch.
This query hits 5 tables, and has a number of joins and other operations. Each operation has a cost displayed here as a percentage of the total query. You’ll notice one operation has a cost of 94%; let’s zoom in.
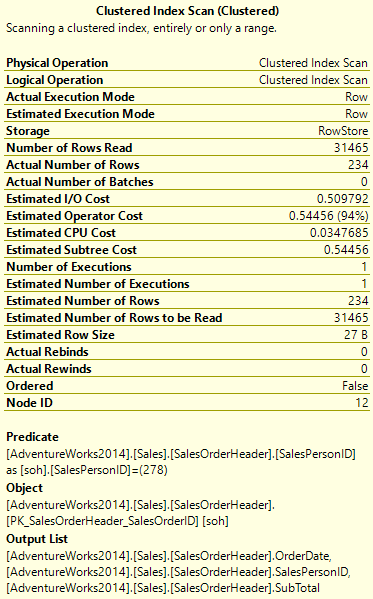
This has a cost of 0.54456. This is broken further into an I/O Cost and a CPU Cost. There is also a Subtree Cost, which would include any operators that feed into this one, but in this case there aren’t any. The operator returned 234 rows, but it read over 31k. So the cost seems appropriate; we really are doing some work here.
The number for cost is always presented without a unit, you may ask 0.54456 of what exactly? Pounds? Parsecs?
Calibration
The story as I recall was that cost was derived from how long it took an early developer of SQL Server to run a given operation on his desktop computer, in seconds. So initially cost was expressed in seconds, but that’s not the case anymore. It’s a more generic expression of how much work is involved in executing the operation.
Given the cost value is fairly generic, you need an idea of what is a cheap operator or an expensive one. Here’s one of the other index seeks from the query above.
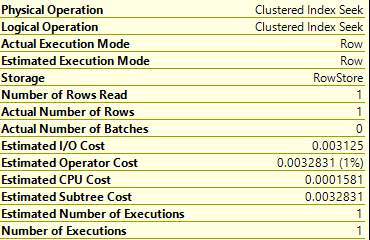
So, we’re doing an index seek not a scan. We not only returned 1 row, we only read one row. In terms of reading a normal table, it’s not going to get any cheaper than this. This cost of about 0.003 is something you’ll see many times for that reason.
So, what constitutes an expensive query? That’s a matter of opinion. You could gauge this by the “Cost Threshold for Parallelism” setting in SQL Server. This is a server level setting that sets how expensive an operation has to be for SQL Server to consider going parallel to perform it. The default setting is 5, so you could argue that’s an expensive query. But this setting is probably quite low for current servers. I think at work, this setting is 100 for most of the servers I work on.
Keep in mind, the cost threshold is for the operation, not the entire plan.
Cost isn’t exact
One thing to remember is that cost in SQL Server is always an estimate. This is a number SQL Server calculates when considering multiple potential plans to determine which would be the best. But the number of rows it expects a given operation to return or how many times that operation runs can be off. All of that is based on statistics.
It doesn’t then go back and update the cost number later if those numbers were incorrect. So while we can use the cost as an indicator of which query or operator we should focus on, don’t completely tunnel-vision that one thing.
I could talk at this point about estimated plans versus actual plans, but fortunately Grant Fritchey has already done so. The gist of his post is that an actual plan is one that has actual runtime metrics. For example, “Number of Rows Read”, “Actual Number of Rows”, and “Number of Executions” in the images above.
It’s helpful to have plans with these actual numbers; they can help you confirm if the costs look accurate. “Number of Rows Read” is the main data point I look at most of the time.
You may also find the following situation in plans as you look at them:
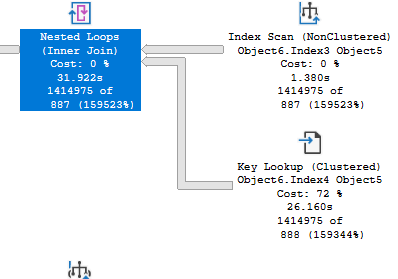
The optimizer estimated 887 or 888 rows for these operators, but the number of rows returned is much higher. So the cost of 72% for the one operator isn’t really accurate. That operator read and returned many more rows, as did the other related operators. If you saw an estimated plan without these runtime numbers, you may come away with a very different impression of how this query is running.
Conclusion
I’ve always felt cost is not well explained, so hopefully this post will help answer some questions. Understanding cost can be really helpful in troubleshooting poorly performing queries, but don’t focus solely on it when analyzing a problem.
If you liked this post, please follow me on twitter or contact me if you have questions.