Hints in SQL Server
I used to be really suspicious of using hints in SQL Server, and now I can’t imagine working without them.
My opinion on this topic changed over the last few years due to a number of the performance issues I’ve worked on. I spoke at SQLSaturday 1000 (Oregon 2020) last weekend, and my talk was primarily about things I learned optimizing garbage collection and similar incremental processes. During that work I ran into a number of issues with queries like this example from the WideWorldImporters database:
DELETE inv
FROM @OrdersGC gc
JOIN Sales.Invoices inv
ON inv.OrderID = gc.OrderID;
Order Matters
The logic here is simple enough. Earlier in the process, we found orders we wanted to delete per retention policy, and put the OrderID values in a memory optimized table variable. We then use the motv to delete from all related tables, and finally the Orders table.
This query doesn’t have a WHERE clause. It’s plain to see how we want this to function though. We have 100 rows in our motv, and we want to delete the related rows in Invoices. But I’ve seen issues caused by execution plans that flip the order:
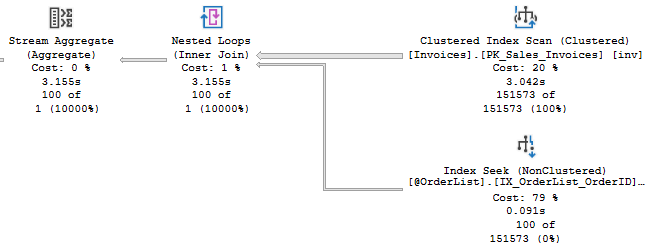
Table variables have no statistics, so the optimizer doesn’t know how many rows to expect from that operation (though table variable deferred compilation in SQL Server 2019 can resolve this) . Occasionally, I would see a plan with a join order that is the opposite of my expectation. The lack of a WHERE clause hurts here, but there’s no clause I can apply that will filter better than the items I already have in my table variable.
Consistency
I work on hundreds of databases with the same schema. They have different data sets and distributions, different sizes, and their statistics are going to update at different times. But if one of them chooses a bad plan, I have to push aside whatever other work to research the high CPU on database xyz.
Consistency is really valuable to me. And in this case, the answer is simple. Yes, I want to scan the fast, small memory-optimized table variable first, and use it to filter the larger, slower table. Adding a join hint or a force order to this query should keeps its plan and performance consistent.
DELETE inv
FROM @OrderList gc
INNER LOOP JOIN Sales.Invoices inv
ON inv.OrderID = gc.OrderID;
DELETE inv
FROM @OrderList gc
JOIN Sales.Invoices inv
ON inv.OrderID = gc.OrderID
WITH OPTION(FORCE ORDER);
Both approaches force the join order. The INNER LOOP JOIN hint has the added benefit of ensuring the plan uses a nested loops join. A hash match wouldn’t be efficient with a batch size of a few hundred or a few thousand. A merge join would likely require a sort of one of the inputs, which defeats the purpose.
Index hints
I had to use index hints in an example I was using in my session for SQLSaturday 1000 (Oregon 2020).
DELETE TOP (@BatchSize) vt
FROM Warehouse.VehicleTemperatures vt
WHERE vt.RecordedWhen < DATEADD(DAY, -180, GETUTCDATE());
This was an example of a garbage collection process. The plan didn’t appear to be a problem, but we should be suspicious of the scan here:
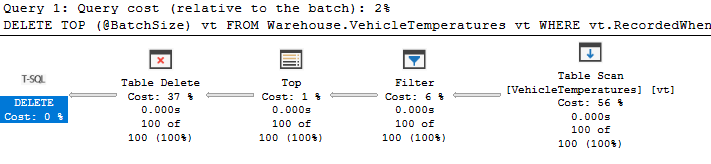
The table scan only read 100 rows, but that’s because there is a TOP operator. The first 100 rows met our filter, so the query ended at that point. If no rows (or less than 100) matched, we would have scanned the entire table.
An index exists on the RecordedWhen column; it just wasn’t used. This is another place where a hint seems obvious. Maybe updating statistics would also resolve the issue, but this gives me more certainty.
DELETE TOP (@BatchSize) vt
FROM Warehouse.VehicleTemperatures vt WITH (INDEX(IX_VehicleTemperatures_RecordedWhen))
WHERE
vt.RecordedWhen < DATEADD(DAY, -180, GETUTCDATE());
With Great Power
By using hints we are taking some of the responsibility away from the SQL Server, and we can cause entirely new problems. Here are some considerations before you try adding a hint.
- Relationships. Make sure you understand the cardinality and relationship between tables. This will inform your expectations about how many rows will be returned where.
- Indexes. Understand what options you have on each table in your query. A table may use one index based on the WHERE clause, or another based on the ON clause. The join order and indexes used are related. An index hint may push SQL Server to a specific join order; vice versa with join\order hints.
- Index hints can break your code! If you use an index hint in a procedure and later drop the index, SQL Server will not politely ignore your suggestion and move on. The procedure will fail until you remove the hint or recreate the index. So, if you use index hints, be aware of this and always check if any hints reference an index before you drop it.
- The most effective filter. If the logic of your statement filters across several tables, consider which one should reduce your result set the most. You probably want that table first in your execution plan.
- Test and test again. The new plans may be completely different from what we imagine, so we really must test our hinted queries and procedures with gusto. Test it for a variety of cases to make sure your code works on realistic data sets. In my case, I will sometimes test against large and small restored databases to make sure it performs as expected.
I’ve heard other engineers speak dismissively of hints, but I would encourage you to not discard a useful tool. Just realize you can cut yourself with it.
One of my coworkers recently resolved a performance issue by changing the join order and forcing it with a hint, or “doing a Jared Poche” in his words. Which shows you how often I’ve used hints, and how often they’ve worked.
Hopefully you learned something from this post. Please follow me on twitter (@sqljared) or contact me if you have questions.