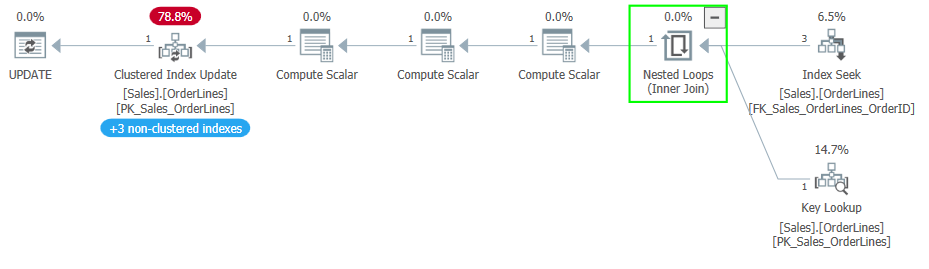
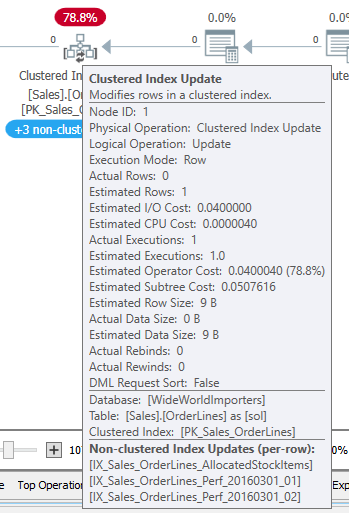
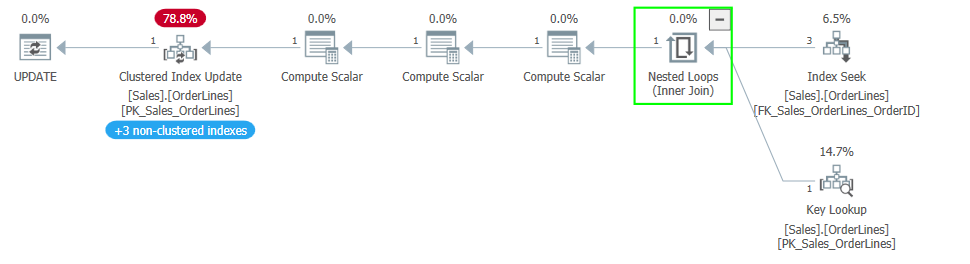
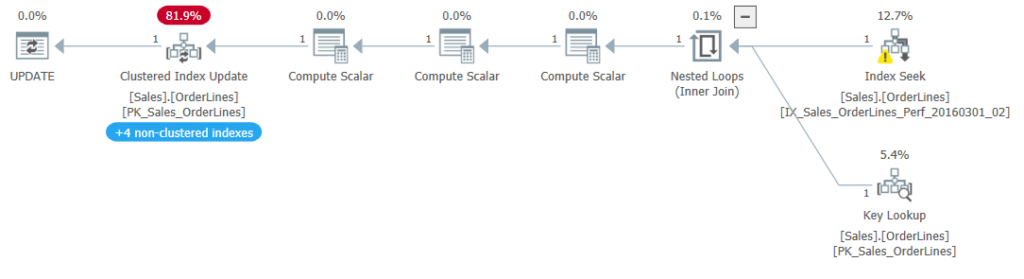
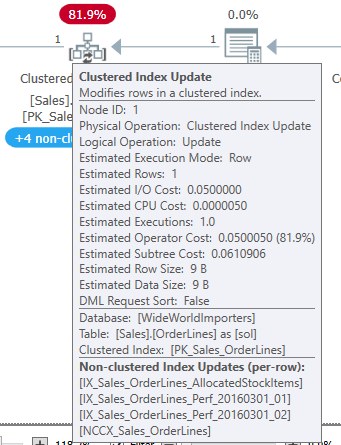
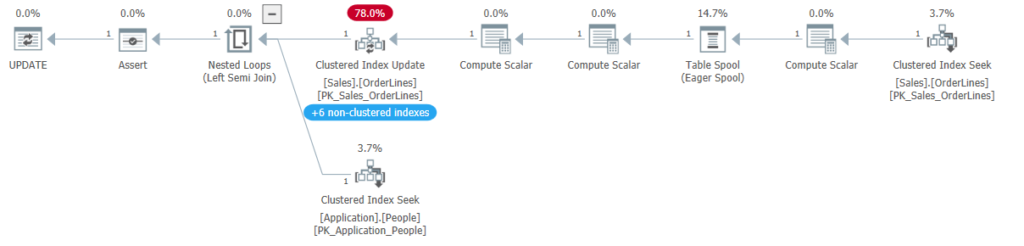
When I saw the Halloween problem for the first time, I was trying to optimize the UPDATE statement in an upsert proc. I had suspected many of the changes to the table were redundant; we were setting the value equal to its current value. We are still doing all the effort of a write to change nothing. The original query was something like this:
/* Original update */
UPDATE ex
SET
ex.value = CASE WHEN @op = 1 THEN tvp.value
ELSE ex.value + tvp.value END
FROM dbo.Example ex
INNER JOIN @tvp tvp
ON tvp.AccountID = ex.AccountID
AND tvp.ProductID = ex.ProductID
AND tvp.GroupID = ex.GroupID
WHERE
ex.AccountID = @AccountID
AND ex.ProductID = @ProductID;
So, I added a WHERE clause to prevent us from updating the row unless we were actually changing the data. If this meant we would write fewer rows, I expected the query would run faster. Instead, the duration and CPU usage increased significantly.
/* WHERE clause changed */
UPDATE ex
SET
ex.value = CASE WHEN @op = 1 THEN tvp.value
ELSE ex.value + tvp.value END
FROM dbo.Example ex
INNER JOIN @tvp tvp
ON tvp.AccountID = ex.AccountID
AND tvp.ProductID = ex.ProductID
AND tvp.GroupID = ex.GroupID
WHERE
ex.AccountID = @AccountID
AND ex.ProductID = @ProductID
AND ex.value <> CASE WHEN @op = 1 THEN tvp.value
ELSE ex.value + tvp.value END;
After discussing with a colleague, we suspected the Halloween problem. So, I read up on the subject and tried to come up with a different optimization for the statement.
I was interested in the idea that the SQL Server optimizer was trying to separate the read phase of the query from the write phase. The eager spool gives SQL Server a complete list of rows it needs to update, preventing the Halloween problem. But the protections made the query take longer.
Description
Well, if SQL Server is trying to separate the read from the write, why don’t I just do that myself? I had the idea to read the data I needed in an INSERT…SELECT statement, writing into a memory-optimized table variable (motv). I could make sure the read included all the columns I need to calculate the new value, including the CASE statement I had in the SET clause of the UPDATE.
I thought of this as Manual Halloween protections but later found Paul White had coined the term about 5 years earlier (look near the bottom of that article).
Why a motv and not a temp table? I found previously that using a temp table in this procedure, which ran hundreds of millions of times per day in our environment, caused a lot of tempdb contention. A table variable would have a similar effect, but not if it is memory-optimized.
This was an upsert procedure, so we will try to update all the rows that correspond to the TVP passed in, and we will insert any rows that don’t exist. Originally, the procedure ran the UPDATE and the INSERT each time, but we already found that we inserted no records the vast majority of the time.
Example
If I query the data into the motv, we can use the motv to decide whether we need to UPDATE or INSERT at all.
/* Manual Halloween; populating the motv */
INSERT INTO motv
SELECT
tvp.AccountID,
tvp.ProductID,
tvp.GroupID,
ex.value,
CASE WHEN @op = 1 THEN tvp.value
ELSE ex.value + tvp.value END
AS new_value
FROM @tvp tvp
LEFT LOOP JOIN dbo.Example ex
ON ex.AccountID = tvp.AccountID
AND ex.ProductID = tvp.ProductID
AND ex.GroupID = tvp.GroupID
WHERE
ex.AccountID = @AccountID
AND ex.ProductID = @ProductID;
I wrote this with a specific join order in mind and used the LOOP JOIN hint to fix the join order as I wrote it, while ensuring we didn’t use a different join type. The table-valued parameter (tvp) input is very likely to have only a few rows in it; less than 5 in almost all cases.
I used a LEFT join as well to account for the possibility that the row isn’t present in the underlying table. If that row doesn’t exist, the ex.value written into the motv will be NULL, and that will indicate we need to insert this row.
But first, let’s look at the update:
/* Manual Halloween; check, maybe UPDATE the base table */
IF EXISTS(
SELECT 1
FROM @motv motv
WHERE
motv.value <> motv.new_value
)
BEGIN
UPDATE ex
SET
ex.value = motv.new_value
FROM @motv motv
LEFT LOOP JOIN dbo.Example ex
ON ex.AccountID = motv.AccountID
AND ex.ProductID = motv.ProductID
AND ex.GroupID = motv.GroupID
WHERE
motv.value <> motv.new_value;
END;
In this case, where we may need to UPDATE or INSERT (but not both for a given row) but also where we suspect the data may not be changing at all, we don’t necessarily have to run the UPDATE statement. First, we query the motv to see if any rows have a value that has changed. If not, we skip the UPDATE.
And I think I should linger on the WHERE clause. The motv.value could be NULL; how does that comparison work? If you compare NULL to a real value, the result is not true or false, it is NULL. Returning NULL for that row won’t cause us to run the UPDATE, which is the correct behavior; we need to INSERT that row.
/* Manual Halloween; check, maybe INSERT the base table */
IF EXISTS(
SELECT 1
FROM @motv motv
WHERE
motv.value IS NULL
)
BEGIN
INSERT ex
SELECT
motv.AccountID,
motv.ProductID,
motv.GroupID,
motv.new_value
FROM @motv motv
WHERE
motv.value IS NULL;
END;
But we only need to INSERT for the rows where that value is NULL.
Takeaways
So, why was this an improvement in this case? There are several points, some I only thought of recently.
- Using Manual Halloween made it easy to reduce the writes to the underlying table for the UPDATE, saving a lot of effort.
- The INSERT statement was also skipped the vast majority of the time.
- Skipping a statement also meant we didn’t run the associated trigger. We also skip foreign key validation on the statement, which can also be quite expensive.
- Fewer writes means fewer X locks on the table, making it less likely we could have contention in a very busy object.
- The separate INSERT SELECT will read the data from the table using SH locks since we know we aren’t writing to the table in that statement.
- The motv uses optimistic concurrency, and we aren’t writing data to a disk for that operation.
In this case, the UPDATE statement only executed 4% of the time the procedure was called. For the INSERT, that number was less than 2%. I wasn’t surprised that the INSERT was unnecessary most of the time; you only insert a row once. I was surprised by how often the lack of an UPDATE indicated the data passed in was unchanged. But we knew this activity was customer-driven and had seen data passed in repeatedly in other places.
In other cases, the Manual Halloween approach may be very effective if the data is redundant. The reduced contention from the fewer writes may also have been a big factor in the improvement. The redundant data may be a very unusual circumstance, though.
It may also be helpful if when there are multiple statements, like in an upsert procedure, where only one is necessary for a given row.
Summary
I have found the Halloween problem fascinating since I was introduced to it, but I’m done with the subject for now. I’ll likely be talking about Query Store next time.
You can follow me on Twitter (@sqljared) and contact me if you have questions. My other social media links are at the top of the page.