In my previous blog, I set up a database with two tables, one with a large CHAR(8000) field and one with a smaller VARCHAR(100) field. Both tables use an INT IDENTITY column for their primary key. Since we’ll be inserting rows sequentially, we will see page latch contention when multiple threads attempt to insert.
We ran some initial tests with SQLQueryStress to create some page latch contention and resolved an odd problem causing connection delays.
We’ll use these two tables and test several different approaches to reduce page latch contention.
OPTIMIZE_FOR_SEQUENTIAL_KEY
This is an option you can use when building an index. This option attempts to control the number of new requests and keep the throughput high. SQL Server does this by prioritizing queries that can complete more quickly.
You will see a drop in PAGELATCH waits, but that’s because they are partly replaced with BTREE_INSERT_FLOW_CONTROL waits. We should include those in our results.
To test this, I’ll need to drop the PK on my existing tables and rebuild them with this option (you could rebuild a clustered index that isn’t a constraint).
For each test, I’ll insert 100 times across each of 100 threads to create a total of 10,000 inserted rows.
Change the clustered index
Since our clustered index is sequential, one option is to use another column (or group of columns) as the clustered index.
Another highly selective column would be ideal. I used the Price column for this test.
When I first tested this, I had left OFSK enabled for the clustered primary key. When I realized this and dropped\recreated without this option, there was virtually no difference (217µs per execution vs 218µs). A further indication that it doesn’t help here.
But what if we still need the IDENTITY column to be indexed for our queries? We can index that column as a nonclustered index. I’ve seen references to page latch contention in the past that discuss this as a problem for clustered indexes only, but I have seen page latch contention on nonclustered indexes before.
I tested again with the Price clustered index, but with a nonclustered index on the IDENTITY column.
Use a computed column
This is another way of indexing a non-sequential column. What if you don’t have another column you want to base your clustered index on? We can make one up.
--Add the new computed column, ModValue
IF NOT EXISTS(
SELECT 1 FROM sys.columns sc
WHERE
sc.name = 'ModValue'
AND sc.object_id = OBJECT_ID('Testing.InsertContention_100') )
BEGIN
ALTER TABLE Testing.InsertContention_100
ADD ModValue AS CONVERT(TINYINT, ABS(InsertID%16)) PERSISTED NOT NULL;
END;
The script above adds a computed persisted column. This is based on the InsertID, but run through a modulus operator. This doesn’t prevent insert contention, but it should spread our inserts across 16 pages in the table.
Partition the table
This extends the computed column from the previous example. If we partition based on the ModValue column, we’ll have 16 separate B-tree structures in our clustered index.
Does this give us an advantage over a clustered index on the same column?
Batch your operations
Instead of having a ton of threads each inserting one row, why not insert them all in one call? If your procedure accepts a table variable (I’d suggest a memory-optimized one) as input, the application can provide 100 rows (or more) in a call.
Fewer threads, less contention.
Each INSERT will take longer, but it tends to be far more efficient to write/read 100 rows in a call rather than to write/read 1 row in each of 100 operations.
If each call inserts 100 rows, I want to still insert 10,000 rows as in my other tests. At first, I ran the test with these options.
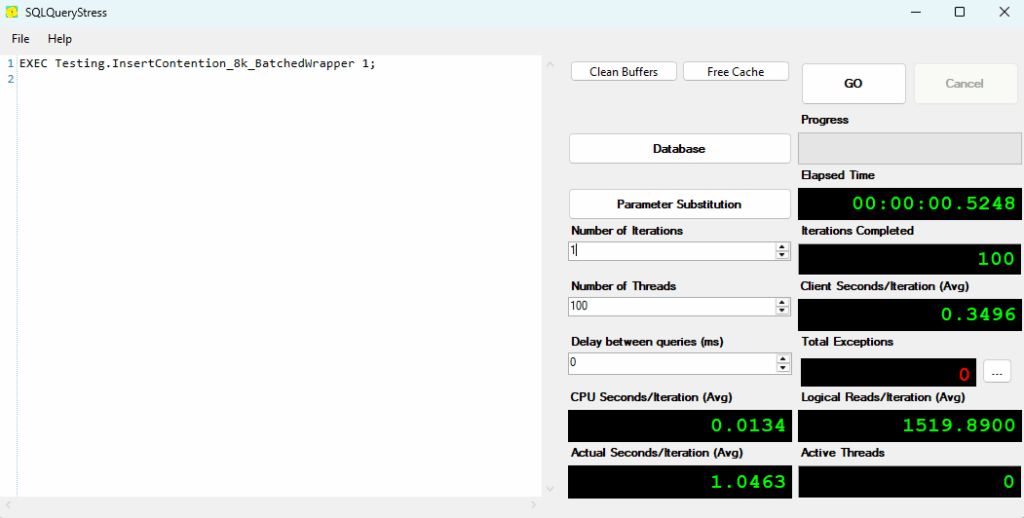
But then I realized my mistake. I had 100 threads call this procedure once, but that’s not the point of batching. I shouldn’t have 100 parallel operations. That may happen if the application receives a large set of data at once and needs to break it down into 100-row chunks.
Otherwise, I would like the application to call as soon as it has 100 rows to insert. So, I ran a second test with 1 thread, but it executed 100 times. This shouldn’t have any page latch contention.
The truth may be in the middle, depending on the inserting application.
Memory-Optimized Table
If the table itself is memory-optimized, we gain optimistic concurrency and remove page latch contention.
Once I saw the result, I decided to do one more variation. I used a memory-optimized table, and batched the inserts into it.
Results
I’ve included my test numbers above. I used separate stored procedures for each test option to make it easy to query the data from Query Store.
- Baseline
- 33.5 seconds total to insert 10,000 rows into the smaller table, 15.8 seconds of that time is PAGELATCH waits.
- 53.1 seconds to insert into the larger table, with 35.5 seconds of PAGELATCH waits.
- CPU time for both is less than 1 second.
- OPTIMIZE_FOR_SEQUENTIAL_KEY
- Little difference for this option. We spend more time waiting if you include the BTREE_INSERT_FLOW_CONTROL waits (recorded in Query Store as ‘UNKNOWN’), but the duration is slightly lower overall.
- If all of the inserts are the same, this option can’t really be effective. If there were more of a mix of simple write statements and more complex statements, there would be more to optimize here. When all the INSERT statements are the same, there’s no advantage.
- Non-sequential Clustered
- Huge improvement.
- 97.7% duration reduction on the small table.
- 96.2% duration reduction on the large table.
- Non-sequential Clustered (ID NC)
- Added a nonclustered index on the InsertID column.
- Slightly better than the baseline for the small table, and a 24.5% reduction for the large table.
- The difference between this test and the previous shows that even one sequential index makes a huge difference, even if it is a nonclustered index.
- Mod PK
- 98.0% duration reduction compared to the baseline for the smaller table.
- 93.6% duration reduction compared to the baseline for the larger table.
- Partitioned Mod PK
- Very similar to the previous test in terms of duration.
- The PAGELATCH waits are lower for the partitioned table compared to simply the mod PK.
- Batched
- This test has 100 threads. Each thread makes 1 call to insert 100 records. Since this is multi-threaded, there is still page latch contention.
- Reduced the duration for the smaller table by about 4/5. Only a 1/3 reduction for the large table.
- The results are better than the baseline, OFSK, and the sequential nonclustered index, but worse than the test with no sequential index or the mod or partitioned PK.
- Batched Single-Threaded
- This test has 1 thread. It calls a procedure 100 times to insert 100 records per call. Single-threaded, so the 0 for page latch waits is expected.
- Best result by far to this point. 20x faster compared to the partitioned mod PK.
- Memory-Optimized
- Inserts into permanent memory-optimized tables. Optimistic concurrency, no PAGELATCH waits.
- Very good, but several times slower than the batched single-threaded test.
- Very little difference between the small and large tables. This could be due to differences in how pages are allocated for a memory-optimized table compared with a physical table.
- Why was the batched approach better? My first thought is the efficiency of having one statement write or read multiple rows.
- Memory-Optimized (Batched)
- What if we used a memory-optimized table, and our application inserted batches of 100 rows?
- Slightly faster than the batched single-threaded insert for the smaller table; several times faster for the large table.
- 22ms to insert 10,000 rows.
Conclusion
Your mileage may vary depending on your server’s configuration, but the results give us three clear tiers.
- The baseline test, OFSK, and the nonclustered sequential index were all relatively bad. The parallel batched test was nearly as slow for the larger table.
- Removing all sequential indexes makes a huge difference. Using the mod PK or a partitioned PK based on the mod column is comparable.
- Memory-optimized tables and batched operations (as long as they aren’t still using a lot of parallel threads) are far more effective.
PAGELATCH waits are a very difficult wait type to address, but hopefully, this will help you fight back against them.
My social media links are above. Please contact me if you have questions, and I’m happy to consult with you if you have a more complex performance issue. Also, let me know if you have any suggestions for a topic for a new blog post.