So let’s talk about the best metric no one thinks about.
A Good Question
I was working with a client troubleshooting an issue several years back now, and they asked a question that was difficult to answer.
We were troubleshooting a slow query, and the reason it was taking so long was oddly opaque.
- It wasn’t blocked
- It wasn’t waiting on CPU or driving the CPU on the server
- It wasn’t waiting on memory
- It wasn’t waiting on the disks
So, the usual suspects were out. We didn’t have the plan for this query yet, and were operating without much information yet. So, the client asked the simple question, “If it isn’t waiting on anything, why isn’t it done?”
I thought it a simple question at first, then I really thought about it. With the usual suspects out, we really couldn’t see what SQL Server was doing. What could be taking up that time?
Invisible culprit
It finally occurred to me that just because we weren’t seeing the disks spike didn’t mean we weren’t doing a lot of reads. Logical reads don’t involve the disks; we’re only reading pages that are already in memory. They are faster than physical reads for sure, but that doesn’t mean they are instant.
The logical reads themselves won’t cause waits. They will use some CPU cycles, but in this case we saw no CPU related wait type or a high overall CPU %.
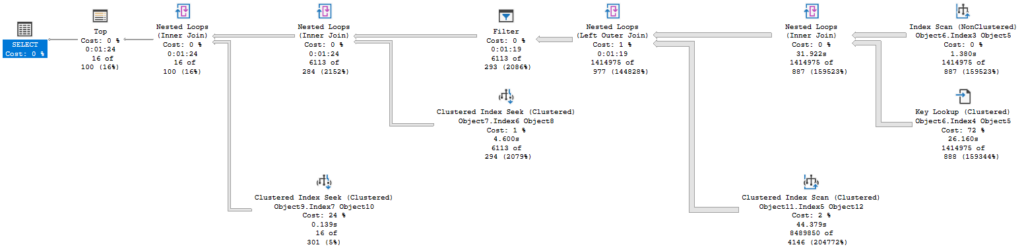
Take the plan above. It took 84 seconds to complete, and only returned 16 rows. But it read millions of rows at the lower levels. If the tables involved are largely in memory, we won’t be waiting on physical IO. It’s a SELECT statement, so it won’t be blocked or blocking if you are using read-committed snapshot isolation level (RCSI, I should blog about that).
With no waits or blocking, how would you see this query is less than optimal unless you are looking for it?
Detecting logical reads
We eventually got the execution plan and it confirmed my suspicion. The plan was reading many, many rows and joining across a number of tables. Once we had the plan, were able to come up with a plan to filter it down faster.
But the lesson here is the effects of logical reads are hard to detect. This makes logical reads a good metric to check for if you want to look at your activity within SQL Server. Here’s an example script for returning the queries with the highest logical reads in the execution cache, centering around sys.dm_exec_query_stats :
SELECT TOP 50
qs.creation_time,
qs.execution_count,
qs.total_logical_reads,
qs.total_logical_reads/qs.execution_count AS ave_logical_reads,
qs.total_elapsed_time,
qs.max_elapsed_time,
qs.total_elapsed_time/qs.execution_count as ave_duration,
substring(t.text, qs.statement_start_offset/2+1,
(CASE WHEN qs.statement_end_offset=-1 THEN (len(t.text)- qs.statement_start_offset)/2
ELSE (qs.statement_end_offset- qs.statement_start_offset)/2 END )+1) AS statement_text,
qp.query_plan,
t.[text],
db_name(t.dbid) as db_name,
OBJECT_NAME( t.objectid, t.dbid) AS object_name,
qs.total_worker_time AS total_cpu_time,
qs.total_worker_time/qs.execution_count AS ave_cpu_time,
qs.total_physical_reads,
qs.total_physical_reads/qs.execution_count AS ave_physical_reads
--,qs.plan_handle, qs.plan_generation_num
FROM sys.dm_exec_query_stats qs
OUTER APPLY sys.dm_exec_sql_text(plan_handle) AS t
OUTER APPLY sys.dm_exec_query_plan(plan_handle) AS qp
ORDER BY qs.total_logical_reads DESC;
GO
This will let you look through the query stats for anything currently in the cache, but of course a restart of SQL Server or another action that clears the cache will mean there isn’t much to see.
If you use Query Store, you could see the queries with the most logical reads in the last two hours with the following:
SELECT TOP 10
SUM(rs.avg_logical_io_reads) AS sum_logical_io_reads,
q.query_id,
p.plan_id,
qt.query_sql_text,
p.query_plan,
rsi.start_time
FROM sys.query_store_query_text AS qt
JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id
JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id
JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
JOIN sys.query_store_runtime_stats_interval rsi
ON rsi.runtime_stats_interval_id =
rs.runtime_stats_interval_id
WHERE
rsi.start_time > DATEADD(HOUR,-2,GETUTCDATE())
GROUP BY
q.query_id,
p.plan_id,
qt.query_sql_text,
p.query_plan,
rsi.start_time
ORDER BY SUM(rs.avg_logical_io_reads) DESC
Conclusion
Another point to consider, while physical reads take more time, the difference between the two is somewhat random. Whether given pages are in memory or not will affect how long a query takes, but we can’t really control what’s in memory without taking unusual measures.
Logical reads will always occur, and should be a more consistent measure of how much work a query requires.
Based on the plan, we may also end up reading to the same page in memory many times, for example if we have a cross product in our query.
I hope you find this post helpful.
If you have any topics related to performance in SQL Server you would like to hear more about, please feel free to @ me and make a suggestion.
Please follow me on twitter (@sqljared) or contact me if you have questions.
Happy Thanksgiving.