I’ve learned a few more items of interest relating to Parameter Sensitive Plan Optimization that I wanted to pass on.
Parameter Sensitive Plan Optimization: Known issue resolved
First, I wanted to point out that there are fixes to issues specific to Parameter Sensitive Plan Optimization in SQL Server 2022. The issue itself is documented at the link below.
When I heard about the issue, I heard that it could cause SQL Server 2022 to cause stack dumps every 15 minutes. The time interval made me think it was related to the default interval for Query Store, and that seems to be the case.
There’s only one known issue documented, but there appear to be updates in CU5 and CU6 for this issue (or some variation of this issue). I’ll link to both below:
https://learn.microsoft.com/en-us/troubleshoot/sql/releases/sqlserver-2022/cumulativeupdate5#2357623
https://learn.microsoft.com/en-us/troubleshoot/sql/releases/sqlserver-2022/cumulativeupdate6#2470755
If you are using PSPO but not encountering this issue, that’s great. But I’d still update as soon as I can.
Don’t be a statistic
I was looking back at a previous blog post and trying to decide why I had not seen PSPO used when I tried testing using the WideWorldImporters database. I had deliberately skewed the data on the Sales.Orders table, and I tried running a procedure with different parameter values that should return a range of row counts.
Nothing.
But the point of PSPO is to take the variable passed in, determine how many rows we should expect it to return, then choose the correct plan based on that cardinality. So, its function depends on checking the histogram for that parameter.
And I hadn’t updated my statistics after I skewed the data…
It worked much better after I updated the stats.
Just thought I would drop that off to save someone else some time.
Odd relationship
With that resolved, I ran a query to see my plans for this procedure. It has only one statement, but I wanted to see the base query, any variants, and their plans. Here’s the query:
SELECT
qsq.query_id,
qsp.plan_id,
qsq.query_text_id,
qsp.plan_type,
qsp.plan_type_desc,
OBJECT_NAME(qsq.object_id),
qv.query_id,
qvp.plan_id,
CAST(qvp.query_plan AS XML),
qv.query_text_id,
qvp.plan_type,
qvp.plan_type_desc
FROM sys.query_store_query qsq
INNER JOIN sys.query_store_plan qsp
ON qsp.query_id = qsq.query_id
LEFT JOIN sys.query_store_query_variant vr
ON vr.parent_query_id = qsq.query_id
LEFT JOIN sys.query_store_query qv
ON qv.query_id = vr.query_variant_query_id
LEFT JOIN sys.query_store_plan qvp
ON qvp.query_id = qv.query_id
WHERE
qsq.object_id = OBJECT_ID('Sales.GetOrders')
ORDER BY
qsq.query_id,
qsp.plan_id,
qv.query_id,
qvp.plan_id;
Here are the results and they were a little surprising.
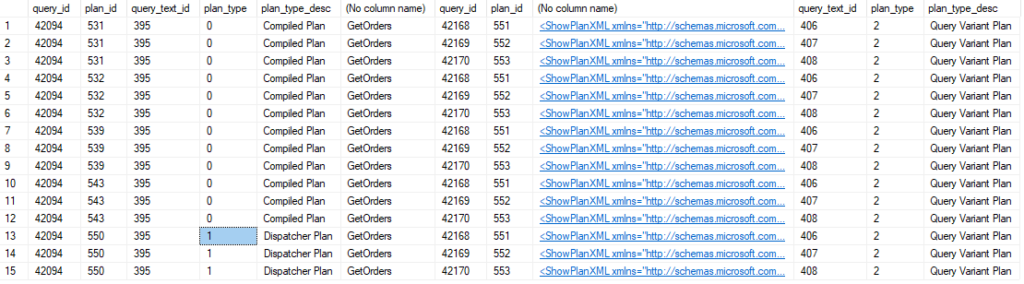
The parent query is the first column, with the dispatcher plan next.
It’s probably not immediately obvious what is odd here. The plan_type and plan_type_desc are included in the result set in columns 4 and 5 for the parent query. The first 12 rows show “Compiled Plan” as its type, but that’s the type for a “normal” query that isn’t using PSPO. So why are all the variant columns populated?
Because the query_id didn’t change once we started using a new dispatcher plan. Since we only joined to sys.query_store_query_variant based on the parent_query_id, we related our variant queries to all plans for the parent_query_id.
Joining on the dispatcher_plan_id as well seems appropriate.
LEFT JOIN sys.query_store_query_variant vr
ON vr.parent_query_id = qsq.query_id
AND vr.dispatcher_plan_id = qsp.plan_id

Yeah, that’s a lot better.
Multiple variables?
A skewed parameter will return a low (less than 100 rows), middle, or high (either more than 100,000 rows or more than 1 million) number of rows. When the optimizer sees the value of the parameter passed in, it gets the cardinality of that value to decide which plan to use.
But SQL Server can vary depending on up to three different parameters for a query. Each parameter has its low, middle, and high thresholds, and plans are created for the various combinations of those parameters.
I recently saw an example of a query using PSPO with multiple parameters. Here’s the dispatcher block of the XML from the anonymized plan for that query:
<Dispatcher>
<ParameterSensitivePredicate LowBoundary="100" HighBoundary="100000">
<StatisticsInfo LastUpdate="2023-02-09T03:47:24.27" ModificationCount="26303" SamplingPercent="86.3454" Statistics="[_statistic_1]" Table="Object1" Schema="Schema1" Database="Database1" />
<Predicate>
<ScalarOperator ScalarString="ScalarString1">
<Compare CompareOp="EQ">
<ScalarOperator>
<Identifier>
<ColumnReference Database="Database1" Schema="Schema1" Table="Object1" Alias="Object3" Column="Column1" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Identifier>
<ColumnReference Column="Column2" />
</Identifier>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Predicate>
</ParameterSensitivePredicate>
<ParameterSensitivePredicate LowBoundary="100" HighBoundary="100000">
<StatisticsInfo LastUpdate="2023-02-09T03:47:24.27" ModificationCount="7831" SamplingPercent="100" Statistics="[index_nonclustered_1]" Table="Object2" Schema="Schema1" Database="Database1" />
<Predicate>
<ScalarOperator ScalarString="ScalarString2">
<Compare CompareOp="EQ">
<ScalarOperator>
<Identifier>
<ColumnReference Database="Database1" Schema="Schema1" Table="Object2" Alias="Object4" Column="Column3" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Identifier>
<ColumnReference Column="Column4" />
</Identifier>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Predicate>
</ParameterSensitivePredicate>
</Dispatcher>
The Dispatcher block has the details for this plan that relate to PSPO.
- The ParameterSensitivePredicate block shows the boundary values for the parameter, and there are two blocks in this plan. Both plans have boundary values of 100 and 100,000.
- The StatisticsInfo block is very useful; it shows the statistic being used to make estimates and its sampling rate. The object and database are also indicated
- The columns that relate to the parameters we are using for PSPO are in the ColumnReference block.
In my case, I saw two plans for the query in question, and if there were any differences they were trivial. Here’s one of the last blocks in the XML plan:
</RelOp>
<ParameterList>
<ColumnReference Column="Column4" ParameterDataType="int" ParameterCompiledValue="Value1" />
<ColumnReference Column="Column8" ParameterDataType="int" ParameterCompiledValue="Value2" />
<ColumnReference Column="Column6" ParameterDataType="bit" ParameterCompiledValue="Value3" />
<ColumnReference Column="Column12" ParameterDataType="int" ParameterCompiledValue="Value4" />
<ColumnReference Column="Column2" ParameterDataType="int" ParameterCompiledValue="Value5" />
<ColumnReference Column="Column10" ParameterDataType="bigint" ParameterCompiledValue="Value6" />
</ParameterList>
</QueryPlan>
Column2 and Column4 are the two related to our PSPO parameters. But there are several other columns that are important to our plan. The ParameterCompiledValue shows the actual value provided for each column when the plan was created. We see “Value1” because this is an anonymized plan.
Using these values, I was able to see how many records we should expect for each using the histogram from our statistics. While the cardinality of Column2 and Column4 may vary a lot depending on the inputs, other columns would not vary as much. Two, in particular, indicated that we would return 1 or a handful of rows at most.
So while the optimizer does the extra work of generating extra plans based on the parameters that have significant skew, the plan is really being driven by other parameters with much lower cardinality.
IN SUMMARY
I’ll post more on this subject as I come across anything new. I will also be presenting a session on Parameter Sensitive Plan Optimization at PASS Data Community Summit in Seattle this November. I hope you’ll consider attending. Last year was my first as a presenter, and I had a wonderful time.
You can follow me on Twitter (@sqljared) and contact me if you have questions. My other social media links are at the top of the page. Also, let me know if you have any suggestions for a topic for a new blog post.