How Relevant is the TOP operator?
I’ve explained what a blocking operator is and provided a few examples, but maybe this doesn’t seem important. It’s affecting the TOP operator, sure, but don’t people just use this to look at the TOP 1000 rows of their tables in SSMS?
The TOP operator is useful for many operations, especially in a large environment. Large operation can timeout or fail for a variety of reasons, consuming resources without providing the results you need. A small, batch-sized operation is more likely to succeed and tends to perform more consistently. Many maintenance operations make sense to run with a TOP operator, so we should make sure those operations aren’t stymied by blocking operators. Some examples:
- Garbage collection on a table with many millions rows. You want this to perform quickly, but you really can’t afford for this to time out (whatever that timeout period may be). We can limit how long this runs by GC’ing a small batch at a time, but this can be hampered badly by an extra sort or a hash join.
- Archiving data applies for the same reasoning as GC. If you archive data to another table\database\server, you’ll want to keep your operation small enough to manage.
- Backfilling a new column. If the existing table is large, you can’t just UPDATE the whole table; you’ll lock the table and block all your users. A batched UPDATE in a loop or in a scheduled process can resolve this without causing an outage.
- GDPR is here, and CCPA is coming. You may need to anonymize data across many related tables. We need this to perform well to cleanse our existing data, and we’ll continue running this process going forward.
- Queries producing potentially large results to your application may need to be batched as well. If this times out, you’re still wasting a lot of time and reads, even if no data is changed.
Out the Window
I examined one process recently that was similar to this query, causing a GC operation to time out.
SELECT TOP 100
inv.InvoiceID,
ili.InvoiceLineID,
ROW_NUMBER() OVER(Partition By inv.CustomerID ORDER BY inv.InvoiceDate) AS SortID
FROM Sales.Invoices inv
JOIN Sales.InvoiceLines ili
ON ili.InvoiceID = inv.InvoiceID
WHERE
inv.InvoiceDate < DATEADD(day, -60, GETUTCDATE())
AND ili.LastEditedWhen < DATEADD(day, -60, GETUTCDATE())
ORDER BY SortID
It was a SELECT statement, and it inserted the important fields into a temp table, and ran DELETEs against multiple tables based on the contents of the temp table. But it was the initial SELECT that had a poor plan and caused the timeout.
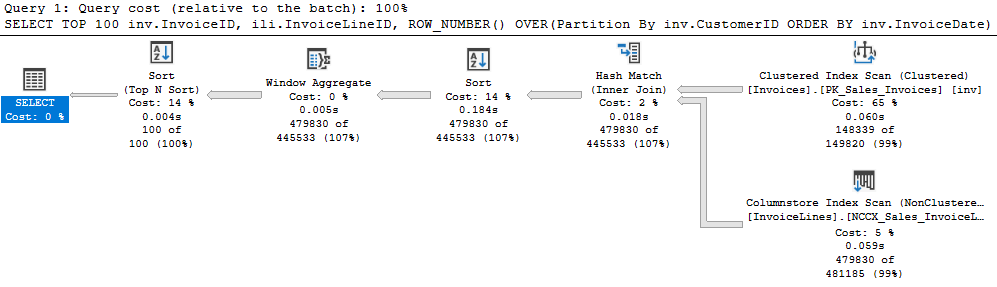
I quickly saw a SORT in the execution plan and wondered why. The actual query didn’t have an ORDER BY clause. But it did have a ROW_NUMBER OVER in the select list; took me a minute to notice that.
But was the sorting necessary? “We need to delete really old records in this table, but it’s vitally important that we delete them in the order they were originally inserted!”
It seemed a poor reason to sort a table with tens of millions of rows. Coupled with the very small batch size, we were doing an extraordinary amount of work to get rid of a few rows. So what if we commented the ROW_NUMBER and the ORDER BY out?
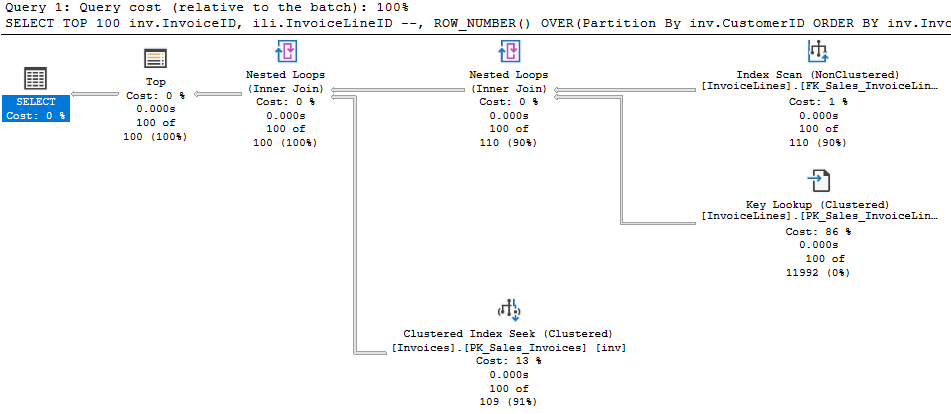
Even though the new plan has a scan operator, we only read 110 rows from it because we are using the TOP operator properly. Note the row counts from the first plan again. We have 479 thousand rows going through multiple operators in the first, but only 100 per operation in the second.
Avoid one Blocking Operator, find another
Here’s an example from recent work. I was looking at a query in a GC that was populating a temp table to use for later DELETEs. I was anticipating the optimizer to try a hash match join, so I used an INNER LOOP JOIN hint to avoid that blocking operator. The results were quite unpleasant, as you can see in this anonymized plan.
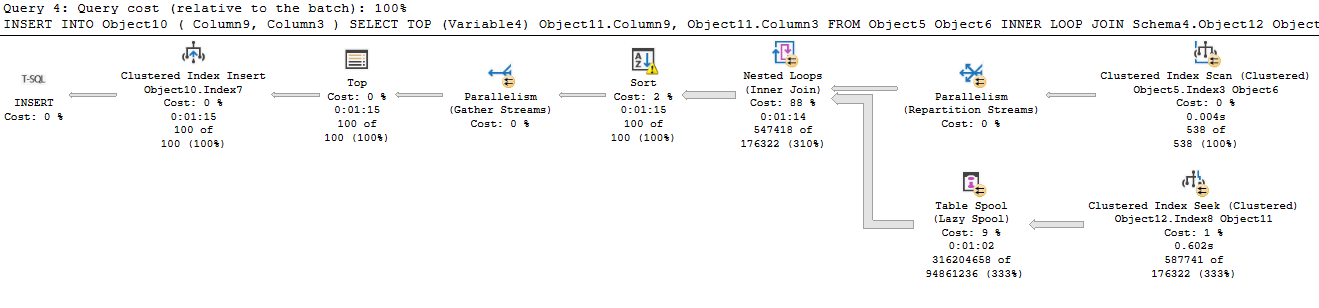
So, I avoided the hash match join, but the SQL Server optimizer didn’t see it the way I did. The first table is a temp table, Object6, which we are joining to a normal table, Object11. But this plan includes a table spool that not only forces us to read all 587741 rows in the seek against our table, it seems to create a cross join in memory between the results of the clustered index scan on the temp table and the clustered index seek against the base table (538 * 587741 = 316204658).
That hint obviously wouldn’t work. I reversed the order of the tables, then removed the hint altogether, giving the following:
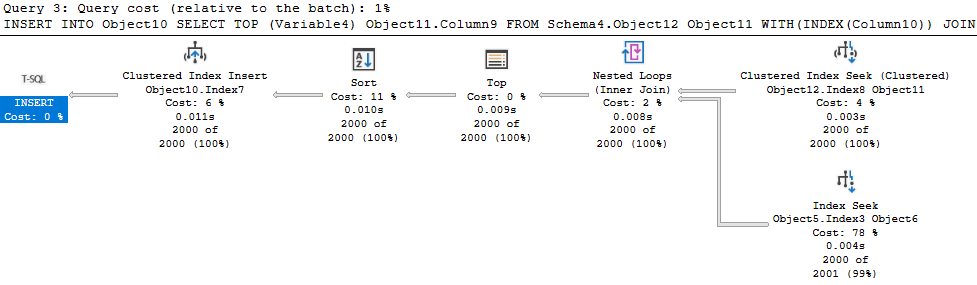
2000 rows returned across the board. There is a SORT operation, but it’s after the TOP so there’s no harm.. Our results are being sorted before inserting them into a second temp table. And a much more performant query, taking ~8 ms instead of 75000 ms.
Sort out blocking operators
Hopefully this has been informative. I honestly wasn’t aware of blocking operators until a month or two ago. That’s the frustrating and interesting thing of SQL Server sometimes; you can work on this as long as I have and, even putting new development aside, there’s always more to learn.
Hope this helps you optimize some of your own operations.