It seems so simple
The TOP operator seems pretty straightforward. “Hey SQL Server, give me the first 100 rows that match this criteria, then stop.” But when certain operations get involved it can go sideways.
Let’s start with a simple example in the WorldWideImporters database.
SELECT TOP 100
sol.OrderLineID,
sol.UnitPrice
FROM Sales.OrderLines sol
WHERE sol.OrderLineID < 1000
AND sol.UnitPrice > 50
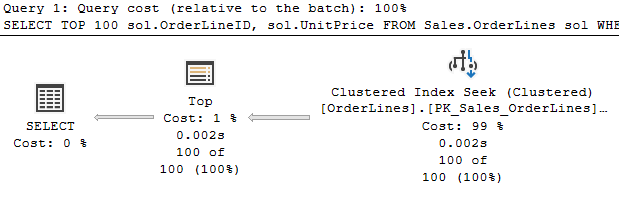
The query here is simple, and we can see the TOP operator only returns 100 rows, but so does the index seek underneath. The way this works is that the TOP asks the operation connected to it for 1 row, and keeps asking until it has 100 or the operation below can’t find anymore rows that match.
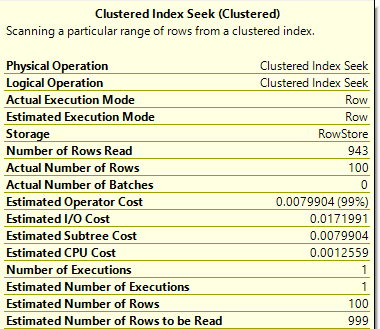
Because of the WHERE clause I chose, we actually had to read 943 rows in the table to get 100 that matched. At that point the TOP stopped asking for more rows.
If the TOP operator kept asking for more rows and only displayed the first 100, that would have been a waste of effort. Still, we’re only querying 1 index here.
Let’s add a wrinkle
SELECT TOP 100
sol.OrderID,
sol.UnitPrice,
sol.Description
FROM Sales.OrderLines sol
WHERE
sol.OrderID < 1000
AND sol.Quantity > 5
ORDER BY sol.OrderID
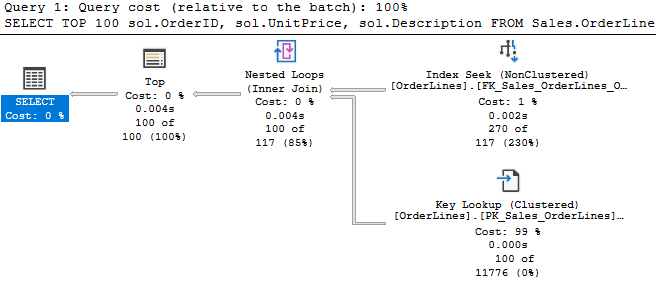
Now we have a key lookup, and we can follow the flow of what happened. We read and returned 270 rows from the index seek. There’s a nested loops operator connecting us to our key lookup, and that returned only 100 rows. So, we had to read 270 rows from the index seek to find 100 rows that met all our filters.
Ultimately the TOP operator was asking for 1 row repeatedly until it met its quota, and then it stopped asking for more. As expected.
What’s a blocking operator?
So, with another change we’ll see one of those operators I mentioned earlier.
SELECT TOP 100
sol.OrderID,
sol.UnitPrice,
sol.Quantity,
sol.PickedQuantity,
sol.LastEditedWhen
FROM Sales.OrderLines sol
WHERE
sol.OrderID < 5000
AND sol.Quantity > 5
ORDER BY sol.LastEditedWhen
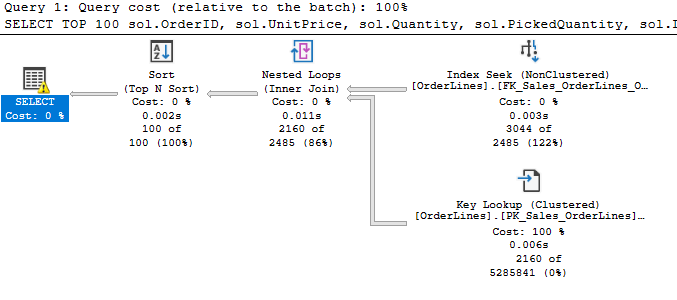
Here, we’re seeking based on a range of OrderIDs, but getting results sorted in a different order. We’re reading many more records from the index and the key lookup (where the estimate is wayyy off). We don’t need to read this much to get our results, because we returned 2160 rows from the key lookup and the nested loops join, but then we reduce when we hit the sort.
It makes sense that you can’t return the top 100 rows that meet this criteria, until you’ve seen them all. Well, unless the data is in the order you want, and you can just seek it that way from the index. Our previous query had an ORDER BY clause but no sort operation because our sort matched our range seek.
Sort is a blocking operator. Don’t feel bad if you haven’t heard of the term; I’ve been working with SQL Server for 15 years, and I’m sure I never heard the term until the incomparable Grant Fritchey mentioned it while he was lecturing at my place of employment.
So sorts and several other types of operators (eager spools, remote query\scan\etc, hash match joins, and more) will block the normal flow and gather all their results before passing any rows on. The hash match join only blocks while building its hash table from the first input, before probing the second.
Let’s hash it out
SELECT TOP 100
so.OrderID,
so.CustomerID,
sol.Quantity,
sol.PickedQuantity,
sol.LastEditedWhen
FROM Sales.OrderLines sol
JOIN Sales.Orders so
ON so.OrderID = sol.OrderID
WHERE
sol.OrderID < 5000
AND sol.Quantity > 5
--ORDER BY sol.LastEditedWhen
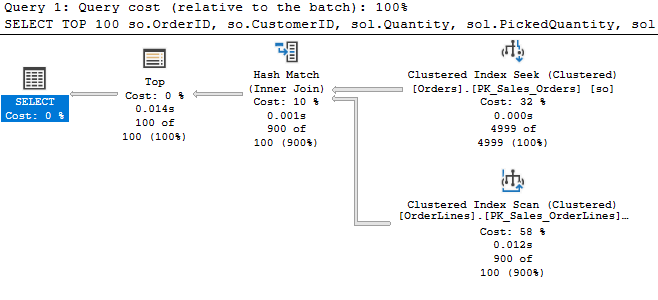
We filtered on OrderID < 5000, and we read 4999 rows from the build table. So we read everything that fit that criteria; we didn’t stop early because we had our 100 rows. So, definitely blocking behavior.
Then we probe the second table and return 900 rows, and they pass through the hash match. The results get reduced to 100 by the TOP operator.
Why 900 rows from the OrderLines table, not 100? That’s less than clear. As I vary the result set or the TOP size, I get a number of behaviors using different indexes and returning batches of various sizes. It appears the probe may be trying to do a batch of rows at a time, or it may be related to the memory allocated. (If I can get a clearer answer to this aspect, I’ll update the post).
Update: I consulted with my colleague, the superb Kevin Feasel, who suggested this was operating in batch mode. I was testing this using SQL Server 2019, and batch mode on rowstore is a new feature that everyone should be aware of.
I thought I had ruled this out however, and indeed the probe operation was in row mode:
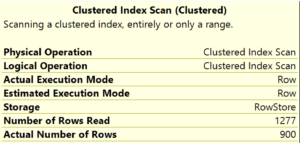
However, the hash match operation was not!

So the hash match requested a batch of 900 rows, which is why we saw the unexpected number of rows.
If you try this in SQL Server 2019, you may see different behaviors as you vary the result set (when I removed LastEditedWhen from the result set, it changed to row mode and only returned 100 rows) or the TOP size (TOP 1000 dropped it back to row mode). I also saw some variation with the index used against OrderLines, including the columnstore index.
Summing up
These have been relatively simple examples of the TOP operator in action, and how it interacts with other operators. In my next post, I’ll provide some more complicated plans, and discuss how we can keep our TOPs in top shape.
sqljared says:
Thanks Kevin!