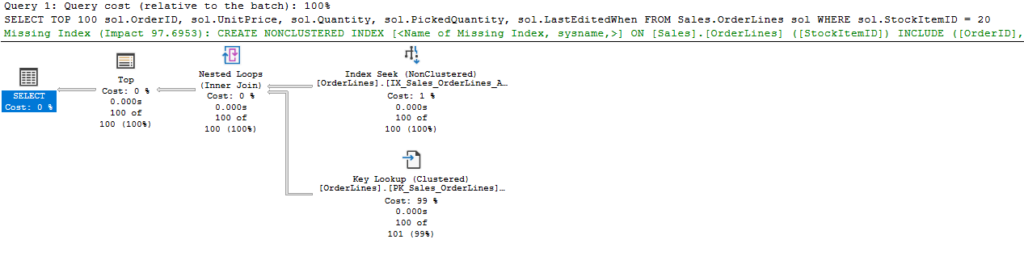
USE WideWorldImporters
GO
SELECT TOP 100
sol.OrderID,
sol.UnitPrice,
sol.Quantity,
sol.PickedQuantity,
sol.LastEditedWhen
FROM Sales.OrderLines sol
WHERE
sol.StockItemID = 20
GO
Key Lookups
In working on my presentation for Data Saturday #8 – Southwest US, I hadn’t realized how many topics come up at least briefly in the talk. I wanted to make a few posts about to go into details on each of these topics and why they are important.
My thanks again to Deborah Melkin for her review and feedback of the presentation.
A key lookup is an operation that occurs when a query has used a nonclustered index on a given table, but needs to access more columns to complete the query. It may need to check columns not in that index for additional filters, or it may just need to return that column as part of its result set.
In the simple query above, we’re retrieving 100 rows from the seek against a nonclustered index, then performing a key lookup against the clustered index. There is a nested loops operator between the two and understanding how that operates is important; for each row we receive from the first table, we perform the second operation once. So, in this query we are seeking 100 rows from the nonclustered index, then performing the key lookup 100 times. We go through the index once for each row we return, and you can see the cost of the key lookup operator is 99% of the query.
Operator Details
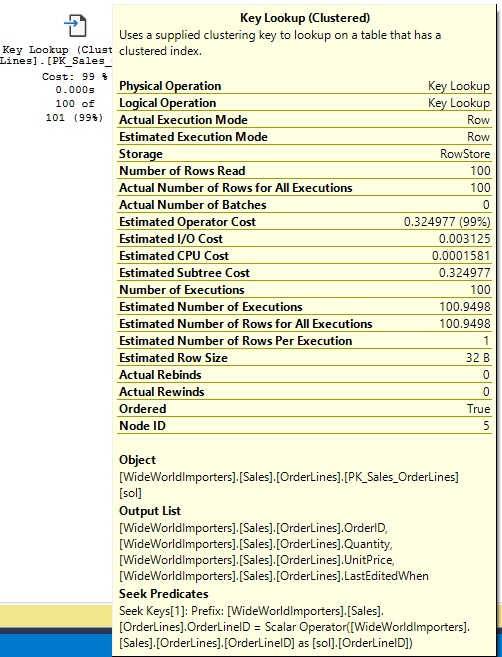
Mouseover
If we mouseover the key lookup, we can see the details of this operation. We actually read 100 rows . The “Estimated Operator Cost” (0.324977) is nearly 100 times that of the index seek (0.0035899).
The “Number of Executions” is 100, so for each row received from the index seek, we traverse the clustered index (its index and leaf pages) once to get that row. And we do 100 separate seeks of that index to get 100 rows. This is a lot more work than we did to get 100 rows with 1 index seek from the nonclustered index.
The estimates match our actuals, but the TOP clause is a very good hint for how many rows we should receive.
If you have a table scan somewhere in your plan is table scanning millions of rows, you should probably address that first. But removing the key lookup by returning fewer columns drops this query from 12.5 milliseconds to 73 microseconds. That’s a 94.16% duration reduction (thank you Query Store).
Resolution
There’s two ways to handle a query like this with a key lookup.
- Do we need these columns in our query?
- Create a covering index.
Addition by Subtraction
We are doing the key lookup because we want to return columns, or filter\otherwise use columns, that are not in the nonclustered index. Let’s first ask this: do we need these columns in our query?
If we check the code or application that’s retrieving the results, does it actually consume those columns from the result set and use them? If we are filtering on that column, does that filter still make sense? If not, let’s just take it out of the query to simplify matters.
And it is very clear which columns are the issue. If you look at the details of the key lookup in the image above, the Output List for that operator shows which columns we are using the clustered index to retrieve. If you don’t need any of them, you can remove them from the query. Your new execution plan will be missing a key lookup.

CREATE COVERING INDEX
The heading is a joke; there’s no such command, of course. A covering index is a nonclustered index that supplies all the information you need from a given table to complete a given query. So far, we’re doing key lookups for this query because no such an index exists. We could get all these columns from the clustered index, but we would have to scan the whole index because our WHERE clause doesn’t match the sorting of the clustered index.
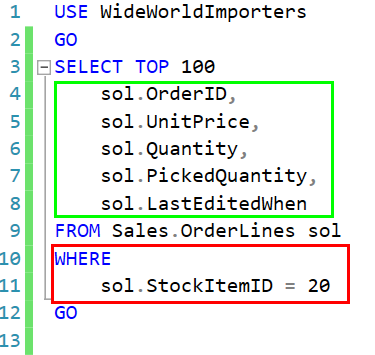
Normally when we create an index, we want our index to include any columns we are filtering on. So it would include columns in our WHERE clause, or the columns in our JOIN clause if we are joining from another table. In some cases, you might want the index to match an ORDER BY. Here just the section in red.
For a covering index on this query, we need to include the SELECT list (in the green section) in our index. In general, every column for this table referenced in the query needs to be in our index.
The INCLUDE column is a great way to add in the columns in our SELECT list.
We could add those 5 columns to our index normally as key values, but that would unnecessarily bloat all the pages of the index. We aren’t filtering on any of those columns, so we don’t need the columns in the index pages for us to filter properly. If we use the INCLUDE clause, these columns will be present only in the leaf page of our index. This is similar to how the columns from the clustered index are added to all nonclustered indexes.
So a script for the new index would look like this:
CREATE NONCLUSTERED INDEX [IX_Sales_OrderLines_AllocatedStockItems] ON [Sales].[OrderLines](
[StockItemID] ASC
) INCLUDE(
[PickedQuantity],
[OrderID],
[UnitPrice],
[Quantity],
[LastEditedWhen]
) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = ON, ONLINE = ON,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [USERDATA]
GO
With the index in place, our original query took 95 microseconds. Slightly longer than the query with the reduced result set, but we did increase the size of the index some.
Conclusion
A key lookup might be an operation you don’t notice often, but I’ve been impressed with the result of removing them when I can.
I’ll be posting other blogs with foundational topics in the near future and more posts in general than I’ve had recently. Maybe this isn’t foundational; it might be on the first floor.
I hope you’ve learned something from this post. Please follow me on twitter (@sqljared) or contact me if you have questions.
1 thought on “Key Lookups”