There are a lot of things to know to understand execution plans and how they operate. One of the essentials is understanding joins, so I wanted to post about each of them in turn.
The three basic types of join operators are hatch match, merge, and nested loops. In this post, I’m going to focus on the last, and I will post on the other two shortly.
How Nested Loops Operate
Nested loops joins are the join operator you are likely to see the most often. It tends to operate best on smaller data sets, especially when the first of the two tables being joined has a small data set.
In row mode, the first table returns rows one at a time to the join operator. The join operator then performs a seek\scan against the second table for each row passed in from the first table. It searches that table based on the data provided by the first table, and the columns defined in our ON or WHERE clauses.
- You can’t search the second table independently; you have to have the data from the first table. This is very different for a merge join.
- A merge join will independently seek or scan two tables, then joins those results. It is very efficient if the results are in the same order so they can be compared more easily.
- A hash join will seek or scan the second table however it can, then probes the hash table with values from the second table based on the ON clause.
So, if the first table returns 1,000 rows, we won’t perform an index seek (or scan) against the second; we will perform 1,000 seeks (or scans) against that index, looking for any rows that relate to the row from the first table.
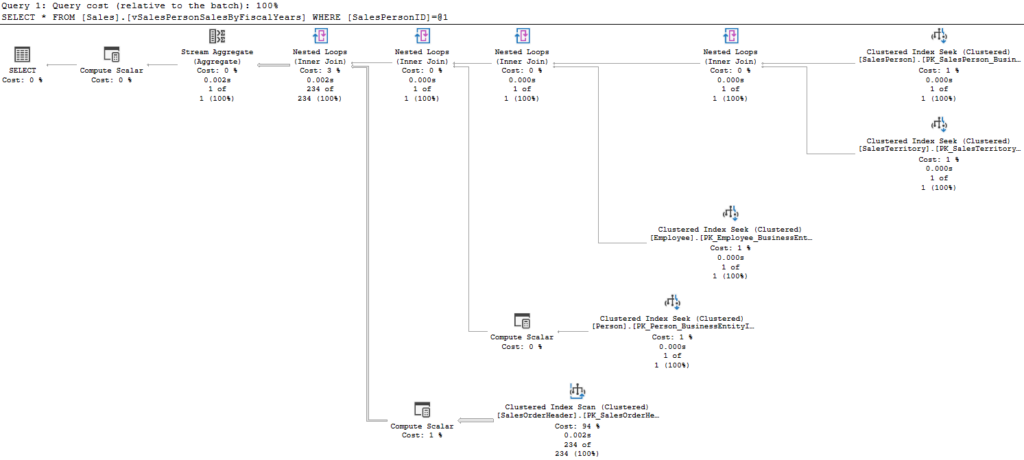
The query above joins several table, using nested loops between each. we can see that the row counts for the first several tables are all 1. We read one SalesPerson record, the related SalesTerritory, an Employee record, and a Person record. When we join that to the SalesOrderHeader table, we find 234 related rows. That comes from 1 index seek, as internal result set only had 1 row thus far. If we join to LineItem next, we would perform that seek 234 times.
Key Lookups
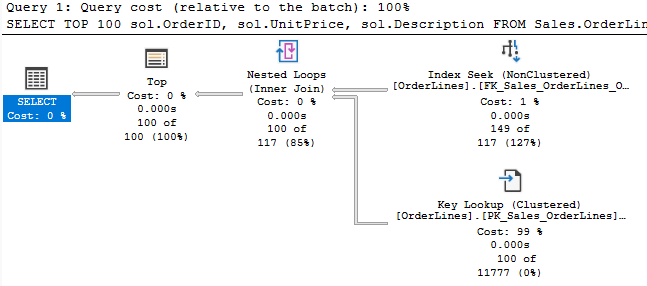
The optimizer always uses nested loops for key lookups, so you’ll see them frequently for this purpose. I was unsure if this was the only way key lookups are implemented, but this post from Erik Darling confirms it.
In the plan above, we return 149 rows from OrderLines table. We use a nested loops join operator so we can include the UnitPrice and Description in our output, since they aren’t in the nonclustered index.
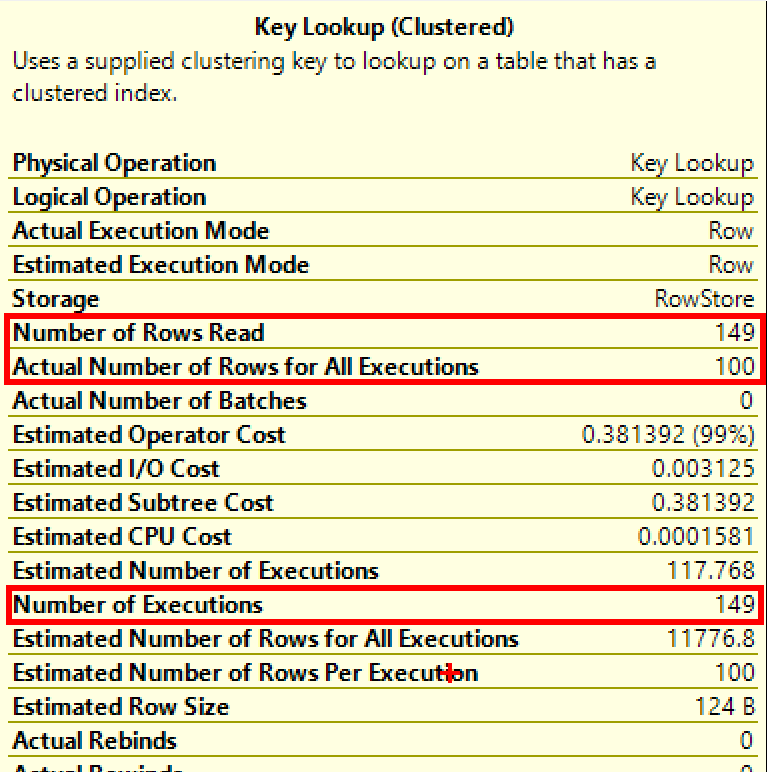
Which means we execute the key lookup 149 times. The cost for this operator is 99% of the total query, but the optimizer overestimated how many rows we would return.
I frequently look at key lookups as an opportunity for tuning. If you look at the output for that operator, you can see which columns are causing the key lookup. You can either add those columns to the index you expect this query to use (as included columns), or you can ask whether those columns really need to be included in the query. Either approach will remove the key lookup and the nested loop.
LOOP JOIN hints
You can direct SQL Server to use nested loops specifically in your query by writing the query with (INNER\LEFT\RIGHT\FULL) LOOP JOIN. This has two effects:
- Forces the optimizer to use the specified join type. This will only force the join type for that specific join.
- Sets the join order. This forces the tables to be joined in the order they are written (subqueries from WHERE EXISTS clauses are excluded from this). So this point may affect how the others joins operate.
I’ve blogged about using hints previously, so I won’t go on for long on this subject. I like the phrase “With great power comes great responsibility” when thinking about using hints to get a specific behavior. It can be an effective way to get consistent behavior, but you can make things worse if you don’t test and follow up to confirm it works as intended.
Summary
I’ll discuss the other two join types in another post. In short, hash matches are more efficient for large data sets, but the presence of a large data set should make us ask other questions. Merge joins are very efficient when dealing with data from two sources that are already in the same order, which is unlikely in general.
Thanks to everyone who voted for my session in GroupBy. I enjoyed speaking at the event, and had some interesting discussion and questions. I expect recordings for the May event will be available on GroupBy’s Youtube page, so keep an eye out for that if you missed the event.
As always, I’m open to suggestions on topics for a blog, given that I blog mainly on performance topics. You can follow me on twitter (@sqljared) and contact me if you have questions. You can also subscribe on the right side of this page to get notified when I post.
Hope you are all enjoying a long weekend.
1 thought on “Nested Loops”