Carrying on from my previous post on the QDS Toolbox, let’s review the Query Waits component.
This component provides details about the wait types associated with a given object, query, or plan. This doesn’t pull data from the reports generated by the Server Top Queries component; this gets the data directly from the Query Store in the database you specify. So you can use this to review the waits on a given procedure, even if you haven’t generated any reports with Server Top Queries .
That being said, reports from Server Top Queries could identify problem queries and give you the PlanID, QueryID, or ObjectName you need to run the procedure. A query that spends a lot of time waiting would tend to have a higher duration and lower active metrics like CPU usage or logical reads. So those are the queries I would want to run the Query Waits report against.
Syntax
Assuming you installed the QDS Dashboard without issue, let’s look at the options for the procedure. @sqlozano documented these in the header of the procedure, for reference. Here’s an example script:
ServerIdentifier: Commented out. I’m gathering data from the instance I’m logged into, which is the default.
DatabaseName: I have a separate database for the QDS Toolbox, so I’m using this parameter to get data from the WideWorldImporters database.
ReportIndex and ReportTable: You can store the data generated by this procedure, and refer to it later. I’m referencing the two tables created by the scripts included in the toolbox. In the header, Pablo included an example that pushes the data to a centralized server across a linked server. You just need to fully qualify the name, like ‘[LinkedSrv].[LinkedDB].[dbo].[CentralizedQueryWaitsIndex]’. If you skip these options, you’ll just get a result set that won’t be saved.
StartTime and EndTime: In my example, I set the EndTime to be current, and the StartTime to be a month ago. So you can specify any reasonable window you want.
ObjectName, QueryID, PlanID: Choose 1 only. The procedure will fail with an error if you provide two. Again, the Server Top Queries output will give you options you can use here.
Verbose Mode: Allows you to see the TSQL generated to produce the report. You could then tweak that query if you want something different in your result set.
TestMode: Enabling this prevents the produced script from actually running.
Output
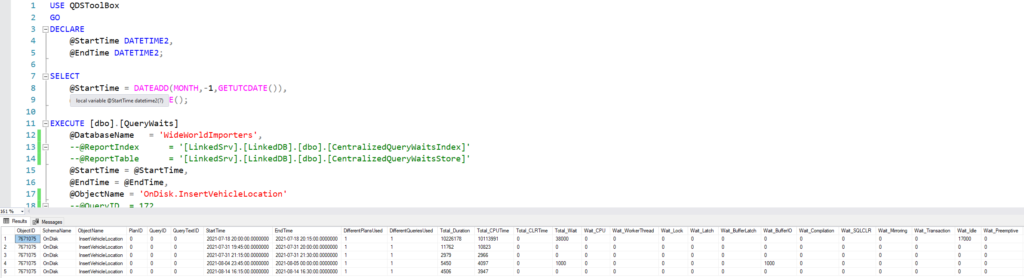
I used the OnDisk.InsertVehicleLocation procedure originally to populate some data in my database (which is part of the World Wide Importers sample on github). Running the Query Waits report to check it’s behavior, this is what the output looks like.
The PlanID, QueryID, and QueryTextID may or may not be returned depending on the input. If you query for a specific QueryID, but it has many associated PlanIDs, this report will only give you one row per interval because it aggregates all the plans together. If they weren’t aggregated, you could have dozens or hundreds of rows per interval.
The results show the numbers from each time interval within the window specified. The duration and CPU time are included, along with the number of plans and queries executed in that interval.
Then we have a lot of columns indicating waits in various categories (I didn’t even include them all in this image). The names here correspond to the types in the page for sys.query_store_wait_stats, so you will need to refer to the table I’ve linked. The WWI workload driver inserts 120,000 rows by default (across 120 threads), and the first interval has data from running that tool.
The data in sys.query_store_wait_stats is in milliseconds, but other tables with performance data like sys.query_store_runtime_stats are in microseconds. This report multiplies the time from sys.query_store_wait_stats by 1000, so if you compare the waits to the duration they have the same units.
There are 17 milliseconds of waits were in the Idle category; this includes a number of things, and it could also be that the tool itself has some delays between batches.
There are also 21 milliseconds of memory waits. This is another category with a number of specific wait types, but both of these seems inconsequential given the procedure took 10,226 milliseconds in this interval. The vast majority of that overall duration is accounted for by the 10,114 milliseconds of CPU time.
So in this case, waits don’t appear to be the issue.
Wrapping up
If I see a query’s CPU usage is much less than half its duration, I’ll usually consider its waits. This is an important aspect of SQL Server performance, and the Query Waits report here makes this data very accessible.
Two down, six more components in the QDS Toolbox. I’ll keep working on these posts, with a few other topics in between.
I hope you find this post helpful. If you have any topics related to performance in SQL Server you would like to hear more about, please feel free to make a suggestion. You can follow me on twitter (@sqljared) and contact me if you have questions.
In having a talk reviewed recently, it was suggested I spend more time defining some of the subject I touched on. It occurred if I should go over (or at least introduce) these ideas during a talk for a SQL Saturday audience, some might find a post on the subject useful. Hence my recent post on key lookups.
Another such topic is table variables. I use table variables frequently at my current job, but they came up very infrequently when I worked at CSS in Microsoft. I remember the conversations about them being very simple at the time, as in, “you should just use temp tables instead.” But there is a lot of utility with table variables, and they could be a useful arrow in your quiver.
Statistics
Table variables are much maligned for one issue; they don’t have statistics.
In most ways, table variables function a lot like temp tables. You can define their columns and insert rows into them. Scoping is different. If you declare a table variable inside a procedure, its scope ends when you return from that procedure. If you create a temp table inside a procedure, it remains for the connection, so the procedure that called the procedure creating the temp table can see the temp table and its contents.
Both can have indexes created on them, but the table variable will have no statistics on its indexes. The result is that the SQL Server optimizer doesn’t know how many rows are in the table variable and will assume 1 row when trying to compare possible execution plans. This may lead to worse plan than you would have with a temp table containing the same data.
This is mitigated in a feature of SQL Server 2019’s Intelligent Query Processor, table variable deferred compilation. This provides cardinality estimates based on the actual number of rows in the table variable, and statements are not compiled until their first execution.
“This deferred compilation behavior is identical to the behavior of temporary tables. This change results in the use of actual cardinality instead of the original one-row guess.”
Microsoft
This feature does require you to be using compatability level 150, but this is a significant upgrade.
Alternatively, if you want to change the behavior around a table variable and aren’t using SQL Server 2019 (or have another compatability mode), you could use a query hint. I’ve used an INNER LOOP JOIN hint many times when using a table variable I expect to have a small number of rows as a filter to find specific rows in a permanent table. This gives me the join order and join type I expect to see, but I’m less shy about hints than many as I have commented previously.
Tempdb contention
There’s an ocean of posts about how to address tempdb contention, mostly focusing on creating enough data files in your tempdb or enabling trace flags that change some behaviors. The point I think that gets understated, is that creating fewer objects in tempdb would also address the issue.
One of the ways table variables function like temp tables, is that they store data in tempdb and can drive contention there as well. The cause of that contention is different, but creating table variables across many different sessions can still cause contention.
Table Valued Parameters
TVPs allow us to pass a table variable to a procedure as an input parameter. Within the procedure, they function as read-only table variables. If the read-only part is an issue, you can always define a separate table variable within the procedure, insert the data from the TVP, then manipulate it as you see fit.
The caveats here are the same; the TVP is stored in tempdb (and can cause contention there), you may have issues with cardinality due to the lack of statistics.
But the advantage is that we can make procedure calls that operate on sets of data rather than in a RBAR fashion. Imagine your application needs to insert 50 rows into a given table. You could call a procedure with parameters for each field you are inserting, and then do that 49 more times. If you do it serially, that will take some time, in part because of the round trips from your application to the SQL Server. If you do this in parallel, it will take longer than it should because of contention on the table. I haven’t blogged about the hot page issue, but that might make a good foundation topic.
Or you could make one call to a procedure with a TVP so it can insert the 50 rows without the extra contention or delay. Your call.
Memory Optimized Table Variables
This changes this by addressing one of the above concerns. Memory optimized table variables (let’s say motv for short), store data in memory and don’t contribute to an tempdb contention. The removal of tempdb contention can be a huge matter by itself, but storing data in memory means accessing a motv is very fast. Go here if you’d like to read the official documentation about memory optimized table variables.
A motv has to have at least one index, and you can choose a hashed or nonclustered index. There’s an entire page on the indexes for motv’s, and more details for both index types on this page on index architecture.
I tend to always use nonclustered indexes in large part for the simplicity. Optimal use of hash indexes requires creating the right number of buckets, depending on the number of rows expected to be inserted into the motv. Too many or too few buckets both present performance issues. It seems unlikely to configure this correctly and then not have the code change that later. It’s too micromanage-y to me, so I’d rather use nonclustered indexes here.
We do need to keep in mind that we are trading memory usage for some of these benefits, as Eric Darling points out amusingly and repeatedly here. This shouldn’t matter the majority of the time, but we should keep in mind that it isn’t free and ask questions like:
Does that field really need to be nvarchar(max)?
I expect this INSERT SELECT statement to insert 100 rows, but could it be substantially more?
What if there are 100 simultaneous procedures running, each with an instance of this motv? Each with 100 rows?
How much total memory could this nvarchar(200) require if we’re really busy?
I certainly would want to keep my columns limited, and you can make fields nullable.
Memory Optimized Table Valued Parameters
So, we can memory optimize our TVP and get the advantages of both. I use these frequently, and one of the big reasons (and this applies to TVPs in general) is concurrency.
So, let’s compare inserting 50 rows of data into a physical table using a normal procedure versus a procedure with a memory optimized table variable.
Singleton Inserts
To test this, I used a tool provided in the World Wide Importers sample on github. Specifically, I was using the workload driver. This was intended to compare the performance of in-memory, permanent tables with on-disk tables, but the setup will work just fine for my purposes.
The VehicleLocation script enables In-Memory OLTP, creates a few tables, procedures to insert into those tables, and adds half a million rows to them. I’ll be using the OnDisk.VehicleLocations table and the OnDisk.InsertVehicleLocation to insert into it.
I wrote the following wrapper procedure to provide random inputs for that procedure:
USE WideWorldImporters
GO
CREATE OR ALTER PROCEDURE OnDisk.InsertVehicleLocationWrapper
AS
BEGIN
-- Inserting 1 record into VehicleLocation
DECLARE @RegistrationNumber nvarchar(20);
DECLARE @TrackedWhen datetime2(2);
DECLARE @Longitude decimal(18,4);
DECLARE @Latitude decimal(18,4);
SET NOCOUNT ON;
SET @RegistrationNumber = N'EA' + RIGHT(N'00' + CAST(CAST(RAND() AS INT) % 100 AS nvarchar(10)), 3) + N'-GL';
SET @TrackedWhen = SYSDATETIME();
SET @Longitude = RAND() * 100;
SET @Latitude = RAND() * 100;
EXEC OnDisk.InsertVehicleLocation @RegistrationNumber, @TrackedWhen, @Longitude, @Latitude;
END;
GO
With this, I basically wrote a loop to call this to individually insert 500 rows. Query Store showed the procedure ran its one statement in 23 µs. I love measuring things in microseconds.
Parallel Inserts
Except that didn’t really test what I wanted. Running it in this fashion in SSMS, it would have run the procedure 500 times serially. I mentioned concurrency as an advantage for memory optimized TVPs, but to see that advantage we need to do singleton inserts into our table in parallel.
A little Powershell later, and I ran this again. I did only 50 inserts, but I did them using 50 parallel threads. Each thread will call the wrapper proc to generate random inserts, then call OnDisk.InsertVehicleLocation.
Since this table has clustered index based on an identity column, we will always be inserting into the last page on the table. But that will require an X lock to write the page, which means our parallel calls will be blocking each other. And the more there are, the worst the waiting will get. This is the hot page issue in a nutshell.
On average each execution took 59 µs. Nearly three times as long. Likely, the first thread completed just as fast as previous, but each subsequent thread has to get in line to insert into the OnDisk.VehicleLocation table. And the average duration increases steadily throughout.
Inserting with a Memory Optimized TVP
Here’s the script I wrote to test using a memory optimized TVP to insert 500 rows.
USE WideWorldImporters
GO
IF NOT EXISTS(
SELECT 1
FROM sys.types st
WHERE
st.name = 'VehicleLocationTVP'
)
BEGIN
CREATE TYPE OnDisk.VehicleLocationTVP
AS TABLE(
RegistrationNumber nvarchar(20),
TrackedWhen datetime2(2),
Longitude decimal(18,4),
Latitude decimal(18,4)
INDEX IX_OrderQtyTVP NONCLUSTERED (RegistrationNumber)
)WITH(MEMORY_OPTIMIZED = ON);
END;
GO
CREATE OR ALTER PROCEDURE OnDisk.InsertVehicleLocationBatched
@VehicleLocationTVP OnDisk.VehicleLocationTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
INSERT OnDisk.VehicleLocations
(RegistrationNumber, TrackedWhen, Longitude, Latitude)
SELECT
tvp.RegistrationNumber,
tvp.TrackedWhen,
tvp.Longitude,
tvp.Latitude
FROM @VehicleLocationTVP tvp;
RETURN @@RowCount;
END;
GO
-- So let's insert 500 rows into this on-disk table using a TVP
DECLARE
@Target INT = 500,
@VehicleLocationTVP OnDisk.VehicleLocationTVP;
DECLARE @Counter int = 0;
SET NOCOUNT ON;
WHILE @Counter < @Target
BEGIN
-- Generating one random row at a time
INSERT @VehicleLocationTVP
(RegistrationNumber, TrackedWhen, Longitude, Latitude)
SELECT
N'EA' + RIGHT(N'00' + CAST(@Counter % 100 AS nvarchar(10)), 3) + N'-GL',
SYSDATETIME(),
RAND() * 100,
RAND() * 100;
SET @Counter += 1;
END;
EXEC OnDisk.InsertVehicleLocationBatched @VehicleLocationTVP;
GO
This creates the type for our memory optimized table variable and defines the procedure. The last batch generates 500 rows of random data, inserting them into the same type, and calls the new proc with the TVP as input. Executing this once to insert 500 rows took 1981 µs, which is just under 4 µs per row.
Full results for all three tests
Wrapping up
This might have been my wordiest blog, but I hope you learned something from it. I’ve rewritten a number of procedures in recent years to operate on batches, and the results have largely been great.
Again, I will frequently use a join or index hint when joining the TVP to a base table, and that’s a minor change that can prevent an expensive mistake from the lack of statistics.
If you have any topics related to performance in SQL Server you would like to hear more about, please feel free to @ me and make a suggestion.
Please follow me on twitter (@sqljared) or contact me if you have questions.